
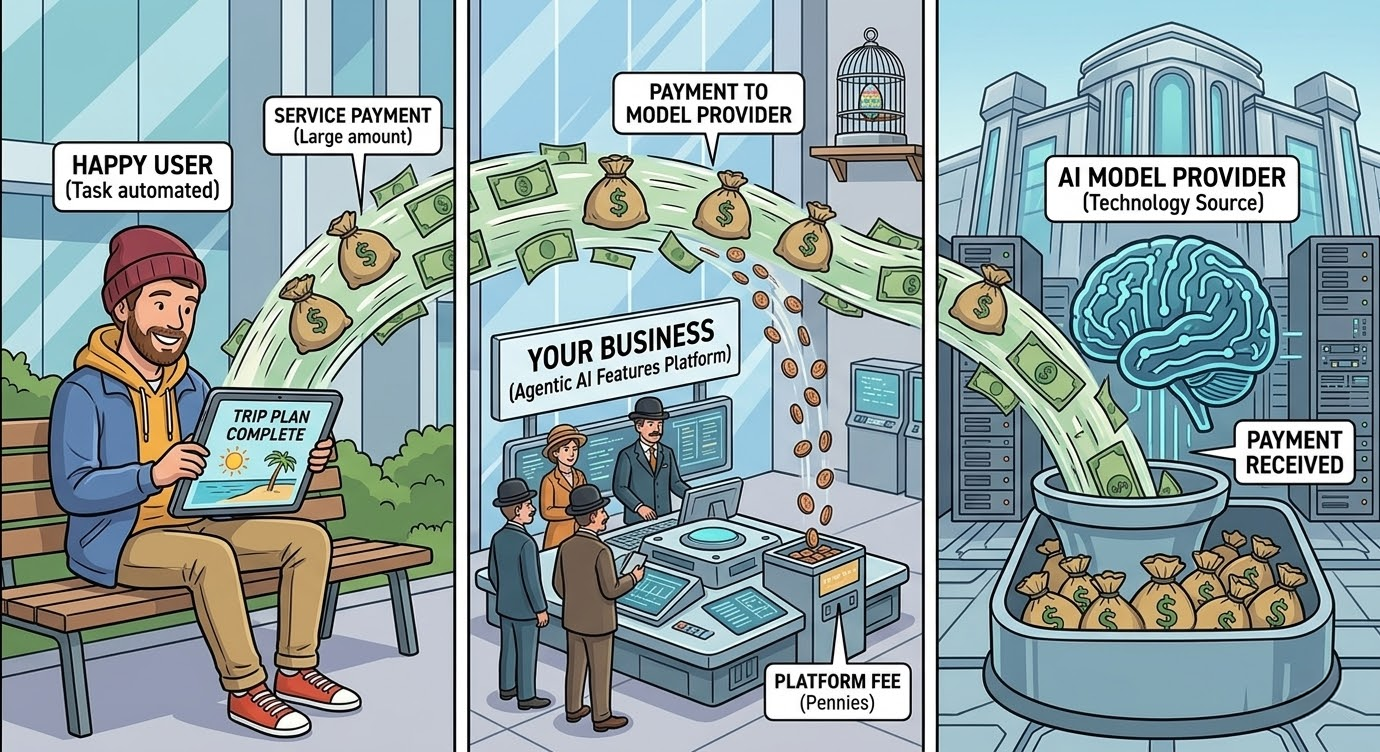
Your best feature may be destroying your margins, and your engineering team has no idea.
This article isn’t about AI as a productivity tool. It’s about AI as a cost structure, embedded in your product, triggered by your users, and scaling with your revenue.
The AI agents embedded in your product are generating a cost structure your pricing model probably didn’t account for. Not a server bill. Not a licensing fee.
A variable, compounding AI infrastructure cost that grows with engagement, spikes with complexity, and, unlike every other line in your budget, gets worse the more your product succeeds.
Every interaction with an LLM-powered feature is a fresh purchase from a model provider, billed per token, at rates that compound with every feature you add to make the product smarter.
The model provider captures guaranteed revenue on every interaction regardless of whether your business ever makes money on that customer. As Andreessen Horowitz has argued, the total cost of ownership for generative AI is reshaping the economics of an entire software category.
AI is running at your expense, not your users
There is a quiet structural problem sitting at the centre of nearly every LLM-powered product business: the more useful your product becomes, the more expensive it is to run.
This is not a temporary inefficiency that engineering will eventually optimise away. It is the defining economic characteristic of a new category of software, and most product teams are not treating it with the strategic gravity it deserves.
The Paradox of the Power User
The most celebrated features of LLM-powered products, personalisation at scale, natural language interfaces, conversational support that actually resolves issues, intelligent document summarisation, share a common characteristic: they get more expensive with use.
The user who engages most deeply generates the most value and the most AI agent cost simultaneously. This inverts one of the foundational assumptions of the SaaS business model. In traditional software, your heaviest users are your best customers.
They renew, they expand, they refer others. In LLM-powered products, your heaviest users may be your least profitable ones.
The user who loves your product enough to use it every day is the one most likely to be costing you more than they pay.
The evidence is not theoretical. GitHub Copilot launched at $10 per month per developer. Microsoft’s internal calculations later revealed that the average developer was costing roughly $30 in Azure compute, with heavy coders consuming up to $80 per month in inference, a product that was operating at negative gross margin from day one for a meaningful subset of its user base.
Microsoft subsequently raised pricing to $19 per month, not because the feature had improved, but because the original pricing had no defensible unit economics.
Sam Altman confirmed publicly that ChatGPT Pro, priced at $200 per month, was losing money on users generating 20,000 or more queries. Cursor, Replit, and others have made similar mid-course corrections, shifting from flat-rate to consumption-based pricing once the distribution of actual usage became visible.
You Can’t Budget What You Can’t Predict
Traditional compute scales linearly: you set a subscription price, model your cohorts, and the unit economics hold. AI agent costs break that contract entirely. You charge your customer a fixed monthly fee decided in a boardroom, while on the other side of that transaction, you are paying a dynamic, usage-driven price to a model provider that doesn’t care about your pricing page.
A user who opens your product twice a month and one who runs complex queries for three hours a day pay you the same amount. They do not cost you the same amount.
The gap between those two numbers isn’t an edge case to be managed — it is the fundamental structural risk of building a subscription business on top of a consumption-based cost model. As Sequoia Capital’s analysis highlights, the AI industry faces a $600 billion question around whether revenue can ever justify the infrastructure spend. You’ve sold certainty to your customer while absorbing all the variability yourself.
You’re not paying per query. You’re paying for every decision, retry, context window, and failure your product accumulates, the per-query figure is just where the math starts.
Start with context window growth. In a multi-turn conversation, each new response requires the model to process every prior token in the session. A 10-turn conversation doesn’t cost 10 times the price of a single turn, it costs closer to 55 times (the sum of 1 through 10), because each turn re-processes everything that came before. Product features designed around conversational depth have costs that escalate with engagement, not proportionally to it.
Then consider the multiplier effect of making your product smarter. Add multi-step reasoning, tool use, or chained agents, and the multiplier compounds further. Research into agentic software engineering found that in multi-agent systems, iterative code review and refinement stages alone consumed nearly 60 per cent of all tokens in a task — not the generation, but the verification loops.
The Reflexion architecture, which gives LLM agents the ability to reflect on and correct their own outputs across multiple trials, achieves impressive accuracy gains precisely because it runs multiple full inference passes per task. Each improvement in output quality is purchased with a corresponding increase in model API costs.
A reasonable unit economics model makes the failure cost concrete. Consider a product with 1,000 daily user interactions, a 70 per cent success rate, and an average lifetime value of $200 per customer.
The 300 daily failures each carry a recovery cost of at least one additional inference call, an escalation probability, and an amortised churn risk. Even conservative assumptions produce a total daily loss that frequently exceeds the entire inference budget. The cost per transaction you’re tracking is the visible part of a larger number.
How Do You Calculate the True Cost of an AI Agent?
There is a mathematical reality about agentic systems that is uncomfortable to confront in a board meeting: the more steps an agent takes, the more likely it is to fail, even when each individual step has a high probability of success.
If an agent executes a ten-step task and achieves 85% accuracy at each step, the compound probability of a fully correct end-to-end outcome is approximately 19%. Four out of every five autonomous task completions produce a result that is wrong somewhere. The arithmetic is a function of sequential dependency, and it does not improve unless you shorten the chain.
The true cost of an agentic system is expressed by this formula:
Expected Agentic ROI = (Task Value × Success Rate × Volume) − (Development Cost + Runtime Cost + Failure Cost)
The term most internal business cases leave blank is Failure Cost. When an agent fails in production, you incur the engineering labor required to diagnose and remediate, plus the business impact of lost customer value. An enterprise deployment processing 1,000 tickets per day at a 70% success rate generates 300 failures daily.
At a conservative $10 per failure, the monthly failure cost reaches $90,000, often exceeding the compute budget. As McKinsey’s State of AI report notes, organisations that fail to account for these hidden costs are systematically underestimating their total cost of ownership.
A demo that works 80 percent of the time is impressive. A production system that fails 20 percent of the time is useless.
5 Proven Strategies to Reduce AI Agent Costs and Architect for Margin
The AI cost structure described above is not fixed. It is simply the default you accept if you deploy without engineering the economics. You should treat unit economics as a first-class architectural concern from day one.
When building cost-effective, production-ready AI agents for enterprise clients, we apply five core AI cost optimization strategies to fundamentally alter the dollar-per-decision profile:
Model Routing by Task Complexity
The costliest assumption in the industry is that every single step of a workflow requires a premium, frontier model. It doesn’t. You wouldn’t pay a senior executive to handle basic data entry, and you shouldn’t pay a frontier model to do it either.
We design heterogeneous architectures that act as intelligent traffic controllers: they route complex, high-entropy planning to advanced models, but immediately delegate the execution of those plans to highly efficient, fine-tuned Small Language Models (SLMs).
This approach isolates the cost of “expensive intelligence” only to the moments it is genuinely necessary, lowering execution costs by 10x to 30x for procedural, repetitive tasks without sacrificing output quality.
Temporal Scheduling & Compute Arbitrage
Not all agentic work is time-sensitive, yet default setups treat every request like an emergency. Heavy computational tasks — like end-of-day batch summarisation, large-scale data extraction, or automated inbox triaging — do not need sub-second latency. We architect systems that explicitly separate real-time user needs from asynchronous background work.
By scheduling heavy processing during off-peak infrastructure hours and batching requests intelligently, we drastically reduce model API costs and prevent latency spikes for the users who actually need real-time responses.
Constraining the Agent’s Latitude
Planning capability is an incredible feature; unconstrained planning is a blank check. Without boundaries, agents will often fall down “rabbit holes,” exploring vast solution spaces and burning tokens in endless loops just to be thorough.
We implement explicit step budgets, tight system guardrails, and hard termination conditions. An agent instructed to resolve a problem in three steps or fewer will often arrive at the exact same result as one told to “do whatever it takes,” but at a fraction of the cost per interaction. This ensures that your per-transaction costs remain predictable and strictly capped.
Prompt Engineering as Infrastructure
Too many development teams treat prompt design as a quick launch prerequisite rather than core, scalable infrastructure. We treat prompts as highly optimised code. By implementing token-budget-aware reasoning, we mathematically force the model to be concise.
Furthermore, we deploy semantic caching at the architectural level. If a customer asks a question today that is contextually similar to one asked yesterday, our system recognises the intent and serves the answer directly from a vector-embedded cache. This bypasses the model provider entirely, routinely slashing direct API costs by 50% to 70% in environments with recurring request patterns.
Difficulty-Aware Adaptive Reasoning
We build automatic cognitive caps into the agent’s reasoning loop to prevent the system from overthinking. Informed by dual-process theories of cognition — distinguishing between rapid, intuitive responses and slow, deliberate analysis — we calibrate our architectures to allocate intensive planning resources only to tasks that actually warrant them.
In AI reasoning, there is a strict point of diminishing returns where accuracy plateaus. We identify exactly where that plateau is for your specific business operations, ensuring you aren’t paying a premium for extra “thinking” that yields zero incremental correctness.
As research on cost-efficient query routing demonstrates, matching model capability to task difficulty is one of the highest-leverage AI cost optimisation moves available.
References
- Shinn, N., Cassano, F., Berman, E., Gopinath, A., Narasimhan, K., & Yao, S. (2023). Reflexion: Language Agents with Verbal Reinforcement Learning. arXiv. https://arxiv.org/abs/2303.11366
- Chen, L., Zaharia, M., & Zou, J. (2023). FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance. arXiv. https://arxiv.org/abs/2305.05176
- Ding, D., Mallick, A., Wang, C., Sim, R., Mukherjee, S., Ruhle, V., Lakshmanan, L.V.S., & Awadallah, A.H. (2024). Hybrid LLM: Cost-Efficient and Quality-Aware Query Routing. ICLR 2024. https://arxiv.org/abs/2404.14618
- Ong, I., Almahairi, A., Wu, V., Chiang, W.-L., Wu, T., Gonzalez, J.E., Kadous, M.W., & Stoica, I. (2024). RouteLLM: Learning to Route LLMs with Preference Data. ICLR 2025. https://arxiv.org/abs/2406.18665
- Regmi, S. & Pun, C.P. (2024). GPT Semantic Cache: Reducing LLM Costs and Latency via Semantic Embedding Caching. arXiv. https://arxiv.org/abs/2411.05276
- Salim, M., Latendresse, J., Khatoonabadi, S.H., & Shihab, E. (2026). Tokenomics: Quantifying Where Tokens Are Used in Agentic Software Engineering. arXiv. https://arxiv.org/abs/2601.14470
- Singla, A., Sukharevsky, A., Yee, L. et al. (2025). The State of AI: How Organizations Are Rewiring to Capture Value. McKinsey & Company / QuantumBlack. https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai-how-organizations-are-rewiring-to-capture-value
- Cahn, D. (2024). AI’s $600B Question. Sequoia Capital. https://sequoiacap.com/article/ais-600b-question/
- Jaipuria, T. (2025). The State of AI Gross Margins in 2025. Tanay Jaipuria’s Substack. https://www.tanayj.com/p/the-gross-margin-debate-in-ai
- Kappelhoff, K. (2025). Unit Economics for AI SaaS Companies: A Survival Guide for CFOs. Drivetrain.ai. https://www.drivetrain.ai/post/unit-economics-of-ai-saas-companies-cfo-guide-for-managing-token-based-costs-and-margins
- Casado, M. & Wang, S. (2023). The Economic Case for Generative AI and Foundation Models. Andreessen Horowitz. https://a16z.com/the-economic-case-for-generative-ai-and-foundation-models/
- Anthropic. (2024). Introducing the Message Batches API. Anthropic Blog. https://claude.com/blog/message-batches-api
- Friedman, D. (2025). AI Startups Are SaaS Minus the Margins. Substack. https://davefriedman.substack.com/p/ai-startups-are-saas-minus-the-margins
- Chaddha, N. (2025). Why AI Margins Matter More Than You Think. Mayfield Fund. https://www.mayfield.com/why-ai-margins-matter-more-than-you-think/

