

Research Report, March 2026 | AscentCore
This research was conducted by AscentCore using a controlled simulation framework that tests AI agent purchasing behavior across competitive marketplaces. For methodology details, replication data, or to run this experiment on your own product category, contact the authors.
1. The Problem: Your Next Customer Isn’t Human
For decades, businesses have invested billions in emotional marketing, brand storytelling, visual appeal, psychological triggers, and aspirational copy designed to persuade human buyers. This playbook is about to become obsolete.
We are entering the era of Business-to-Agent (B2A) commerce, where AI agents act as autonomous purchasing proxies on behalf of consumers and enterprises alike. These agents don’t see your logo. They don’t feel your brand story. They don’t respond to urgency tactics or aspirational imagery. They read your product data, reason over it algorithmically, and make selections based on structured logic.
The stakes are existential. Our research demonstrates that when an AI agent selects products on behalf of a user, the agent’s choice diverges from the objectively best option over half the time, and the primary cause is how the product is described. This means that right now, today, the way your product data is structured is actively determining whether an AI agent recommends you or your competitor.
Why CEOs and CFOs Must Act Now
The shift is not theoretical, it is already happening. AI assistants are recommending financial products, selecting insurance policies, choosing service providers, and curating meal subscriptions.
If your product data isn’t optimized for agent consumption, you are already losing revenue to competitors whose data is. The companies that treat their product descriptions as core infrastructure, not as marketing afterthoughts, will own the AI-native economy. Those that don’t will become invisible to the fastest-growing purchasing channel in history.
This report presents the findings of a controlled experiment that quantifies exactly how much influence product descriptions have on AI agent decision-making, and provides a concrete roadmap for optimization.
2. The Experiment: Simulating Real-World Agent Purchasing Decisions
Objective
We designed an experiment to answer a single critical question: When an AI agent makes a product selection on behalf of a user, how much does the product’s public-facing description influence the outcome and does that influence lead to better or worse choices?
Methodology
Our experiment simulates realistic competitive marketplaces across multiple industries. For each simulation, we follow a rigorous, reproducible process:
Step 1: Create the Competitive Landscape. We generate a complete marketplace for a given product category, including multiple competing businesses, each following a distinct business strategy (premium quality, value leader, or innovation-first). Each business offers one or more products.
Step 2: Define Dual-Layer Product Data. For every product, we create two distinct layers of information:
- Agent Data (Public Layer): The marketing description, price, and any information a customer or AI agent could discover on a webpage or through an API. This is the “storefront”, the copy that is meant to sell.
- Internal Quality Evaluation (Hidden Layer): A candid, internal-only assessment of the product’s true quality, sourcing, operational issues, cost-cutting measures, and real performance. This is the “ground truth”, the information a human might discover through deep research, reviews, or insider knowledge, but which is never exposed to the AI agent.
Step 3: Generate Realistic User Queries. We create natural-language queries that sound like real people talking to a smart assistant (e.g., “Find me the absolute cheapest home insurance that won’t leave me high and dry if my pipes burst”). Each query carries a primary intent (e.g., lowest price) and a secondary intent (e.g., brand trust / reliability).
Step 4: Run Two Parallel Agent Evaluations. For each user query, we execute the AI agent twice under two distinct conditions:
- Full-Data Agent: Has access to all information, public descriptions, prices, AND internal quality evaluations. This agent makes the “ground truth” optimal selection.
- Description-Only Agent: Has access ONLY to public marketing descriptions and prices. No internal data. This agent represents a real-world AI assistant selecting products on behalf of a user.
Step 5: Compare and Analyze. We compare the two selections. When they match, the description successfully communicated the product’s true value. When they diverge (mismatch), the description either misled the agent or failed to convey critical information resulting in a suboptimal recommendation for the user.
Scale of the Experiment
We ran this experiment across 5 distinct product categories spanning both consumer goods and complex services:
# | Product Category | Businesses | Products per Business | User Queries |
1 | Food Truck: Burgers | 34 | 4 | 3 |
2 | House Painting Services | 48 | 1 | 5 |
3 | Home Insurance Policies | 12 | 1 | 5 |
4 | Monthly Meal Kit Subscriptions | 8 | 3 | 3 |
5 | Financial Services: Credit Cards | 6 | 3 | 3 |
Total | 19 |
Why This Is Close to the Real Thing
This experiment closely mirrors how AI agents operate in the real world for three critical reasons:
- Agents don’t have insider access. When a user asks an AI assistant to find them a credit card or a painting service, the agent works with whatever public data it can retrieve, product pages, descriptions, and prices. Our “description-only” condition replicates this exactly.
- The competitive dynamics are realistic. Each marketplace contains businesses following different strategies (premium, value, innovation) with products at varying price points and quality levels, just like a real market.
- The queries are human. Our user queries are phrased as natural language with layered priorities (e.g., “cheapest but also reliable”), reflecting how real people actually talk to AI assistants.
3. Use Cases: Where This Research Applies
The implications of this research extend far beyond a single industry. Any business whose products or services are evaluated by AI agents faces the same fundamental challenge. Here are the primary use cases:
Use Case 1: E-Commerce Product Selection
When a consumer asks an AI assistant to “find me the best wireless headphones under $100 with good noise cancellation,” the agent retrieves product descriptions from multiple retailers and makes a recommendation. Our research shows that the product with the most strategically worded description, not necessarily the best product wins.
Use Case 2: Financial Product Comparison
Credit cards, insurance policies, loans, and investment products are increasingly selected by AI agents acting as financial advisors. Our experiments on credit cards and home insurance demonstrate that agents can be steered toward products with hidden drawbacks (high APR, coverage exclusions, claim denial rates) when the public description obscures these facts.
Use Case 3: B2B Service Procurement
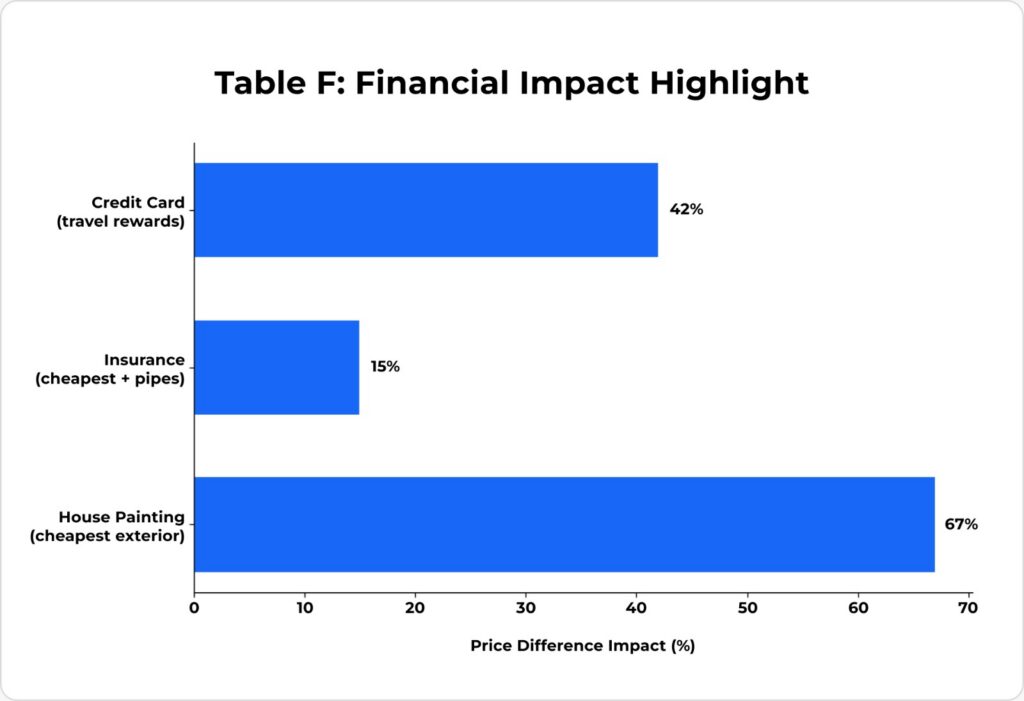
When an enterprise AI agent evaluates painting contractors, software vendors, or consulting firms, it relies on public-facing service descriptions. Our house painting experiments reveal that a single ambiguous phrase in a description can cause the agent to disqualify the cheapest viable option and select one that costs 67% more.
Use Case 4: Subscription Service Recommendations
Meal kits, SaaS products, streaming services, any subscription model where an AI agent compares options on behalf of a user. Our meal kit experiments show that descriptions emphasizing eco-friendly sourcing language can override a user’s explicit request for sustainable packaging when the description doesn’t mention packaging at all.
Use Case 5: Marketplace Ranking and Visibility
As dynamic tool marketplaces emerge (where AI agents autonomously discover and procure capabilities), your product’s description becomes its entire identity. Products with poorly structured data won’t just lose sales they’ll never even be considered.
4. Results: The Data Speaks
4.1 Overall Match Rate
Across all 5 product categories and 19 valid agent decisions, we measured how often the description-only agent selected the same product as the full-data (ground truth) agent.
Metric | Value |
Total Valid Decisions | 19 |
Matches (Correct Selection) | 9 |
Mismatches (Suboptimal Selection) | 10 |
Overall Match Rate | 47.4% |
Overall Mismatch Rate | 52.6% |
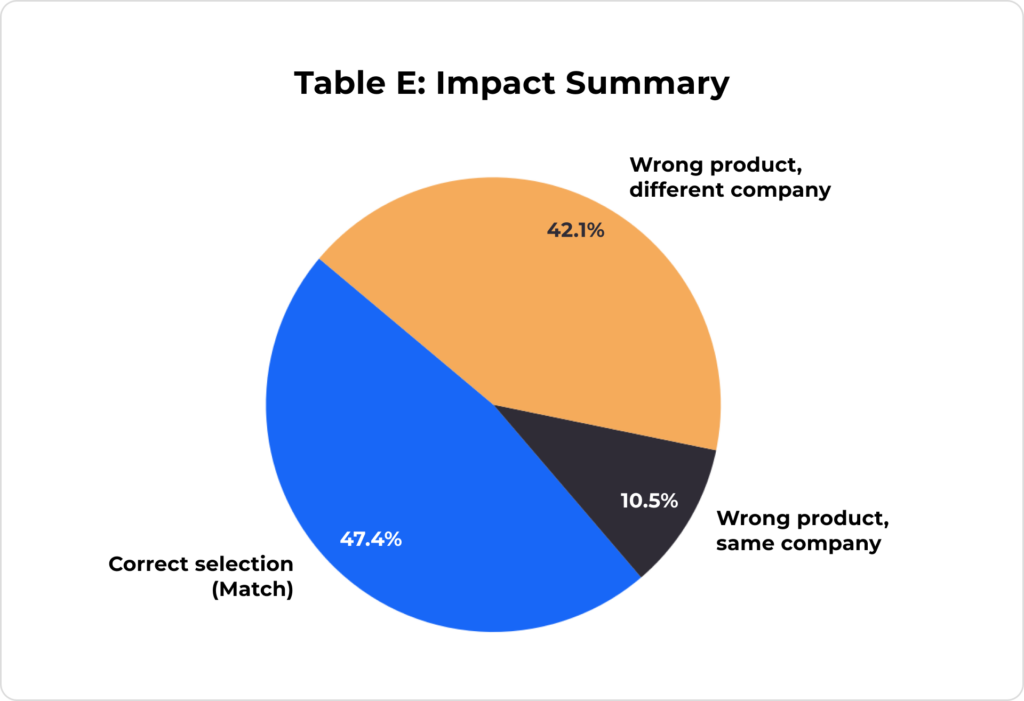
Note: One insurance query (Query 5) produced an agent error and was excluded from category-level analysis, but is counted in the overall total as a failure case, the agent could not complete the selection at all, which is itself a suboptimal outcome.
Key Finding: When AI agents rely solely on marketing descriptions, they make a suboptimal choice more than half the time.
4.2 Match Rate by Product Category
Product Category | Queries | Matches | Mismatches | Match Rate |
Food Truck: Burgers | 3 | 1 | 2 | 33.3% |
House Painting Services | 5 | 2 | 3 | 40.0% |
Home Insurance Policies | 4* | 2 | 2 | 50.0% |
Meal Kit Subscriptions | 3 | 2 | 1 | 66.7% |
Credit Cards | 3 | 2 | 1 | 66.7% |
Overall (excl. error) | 18 | 9 | 9 | 50.0% |
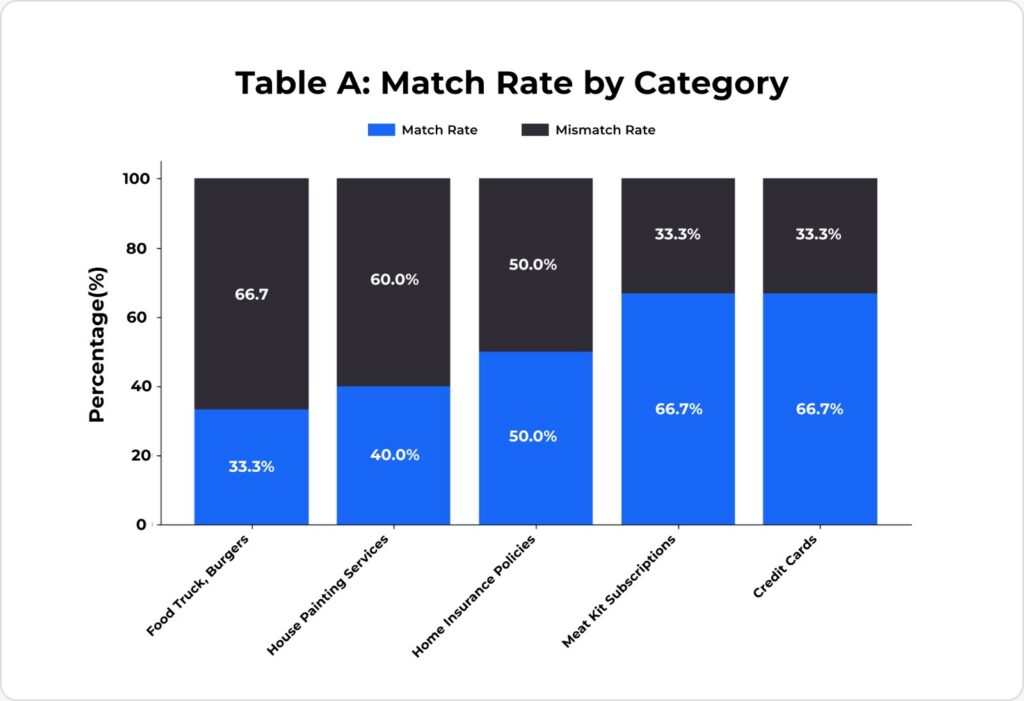
Note: One insurance query produced an error and was excluded.
Insight: More complex, high-stakes product categories (services, insurance) have lower match rates. Products where a single quantitative attribute dominates (price for credit cards, unique features for meal kits) show higher match rates.
4.3 Detailed Decision Outcomes by Experiment
Experiment 1: Food Truck: Burgers (12 competitors, 1 product each)
Query Intent | Priorities | Full-Data Selection | Description-Only Selection | Status |
Cheapest decent burger | lowest price, brand trust | The Double Stack (Simple Stacks) | The Classic Value Burger (BurgerBite Express) | Mismatch |
Grass-fed gourmet, price no object | brand trust, eco friendliness | The Truffle Baron Burger (The Gilded Griddle) | The Heritage Burger (Prime Cut Provisions) | Mismatch |
Creative plant-based alternative | innovation, eco friendliness | The Myco-Miso Meltdown (The Umami Engine) | The Myco-Miso Meltdown (The Umami Engine) | Match |
Experiment 2: House Painting Services (12 competitors, 1 product each)
Query Intent | Priorities | Full-Data Selection | Description-Only Selection | Status | Impact |
Cheapest exterior paint | lowest price, brand trust | All-Inclusive Refresh ($15/sqm) | Signature Estate Finish ($25/sqm) | Mismatch | +67% cost |
Most durable exterior paint | durability, brand trust | Signature Estate Finish (Prestige) | ThermoShield Pro (Aura Smart) | Mismatch | Wrong process |
Zero-VOC for kid’s room | eco friendliness, brand trust | BioLuxe Wall Coating | BioLuxe Wall Coating | Match | – |
Trusted interior service | brand trust, durability | Signature Estate Finish (Prestige) | The Estate Finish (Gilded Brush) | Mismatch | Unverified claims |
Modern self-cleaning exterior | innovation, durability | ThermoShield Pro | ThermoShield Pro | Match | – |
Experiment 3: Home Insurance Policies (12 competitors, 1 product each)
Query Intent | Priorities | Full-Data Selection | Description-Only Selection | Status | Impact |
Cheapest, covers burst pipes | lowest price, brand trust | FoundationGuard (HavenSure) | Homestead Shield Essentials (AnchorPoint) | Mismatch | Excludes water backup |
Best flood/wind, reputable | durability, brand trust | Sovereign Estate Shield | Sovereign Estate Shield | Match | – |
Green home discounts + app | eco friendliness, innovation | SmartShield Proactive | SmartShield Proactive | Match | – |
Smart home discounts | innovation, lowest price | SmartShield Proactive | Guardian Shield Policy | Mismatch | Different product entirely |
20-year history + modern | brand trust, innovation | – | – | Error | Agent failure |
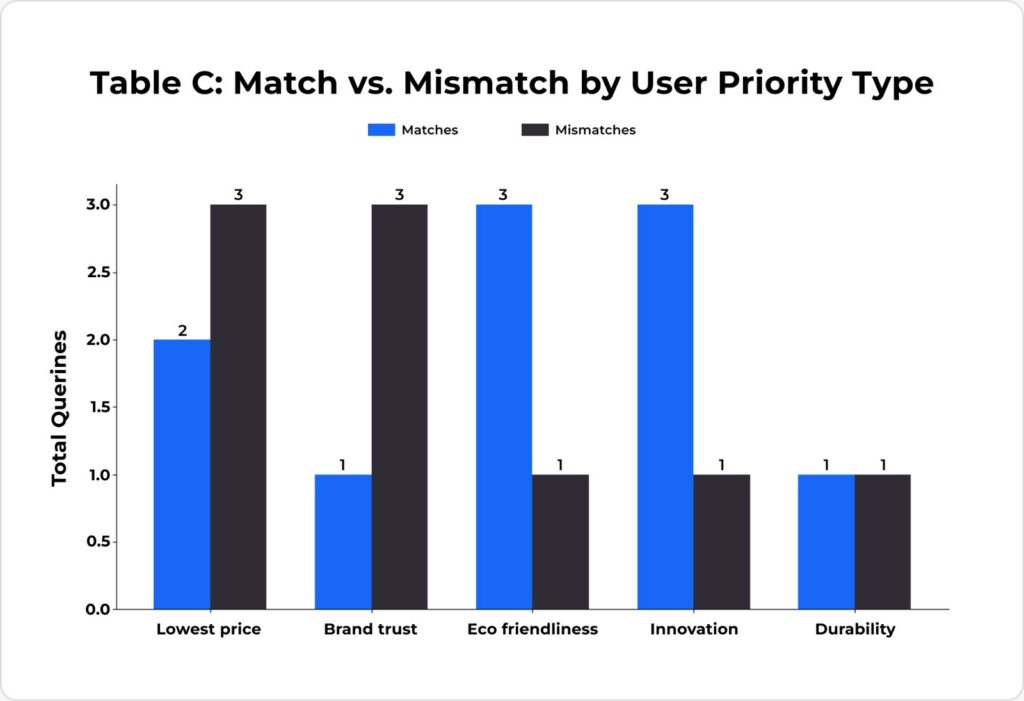
Experiment 4: Meal Kit Subscriptions (6 companies, 3 products each)
Query Intent | Priorities | Full-Data Selection | Description-Only Selection | Status |
Cheapest with 4-star quality | lowest price, brand trust | The Veggie Value Box | The Veggie Value Box | Match |
Eco packaging + stays fresh | eco friendliness, durability | The Homesteader’s Box | The Gardener’s Delight | Mismatch |
International fusion under $12 | innovation, lowest price | The Fermentation Frontier Kit | The Fermentation Frontier Kit | Match |
Experiment 5: Credit Cards (6 companies, 3 products each)
Query Intent | Priorities | Full-Data Selection | Description-Only Selection | Status |
Lowest fee + low interest rate | lowest price, brand trust | Foundation Starter Card | Foundation Starter Card | Match |
Travel rewards + trip insurance | brand trust, durability | The Obsidian Card | The Voyager Card | Mismatch |
Eco-friendly + recycled + app | eco friendliness, innovation | EcoSpend Visa Terra | EcoSpend Visa Terra | Match |

4.4 Root Cause Analysis of Mismatches
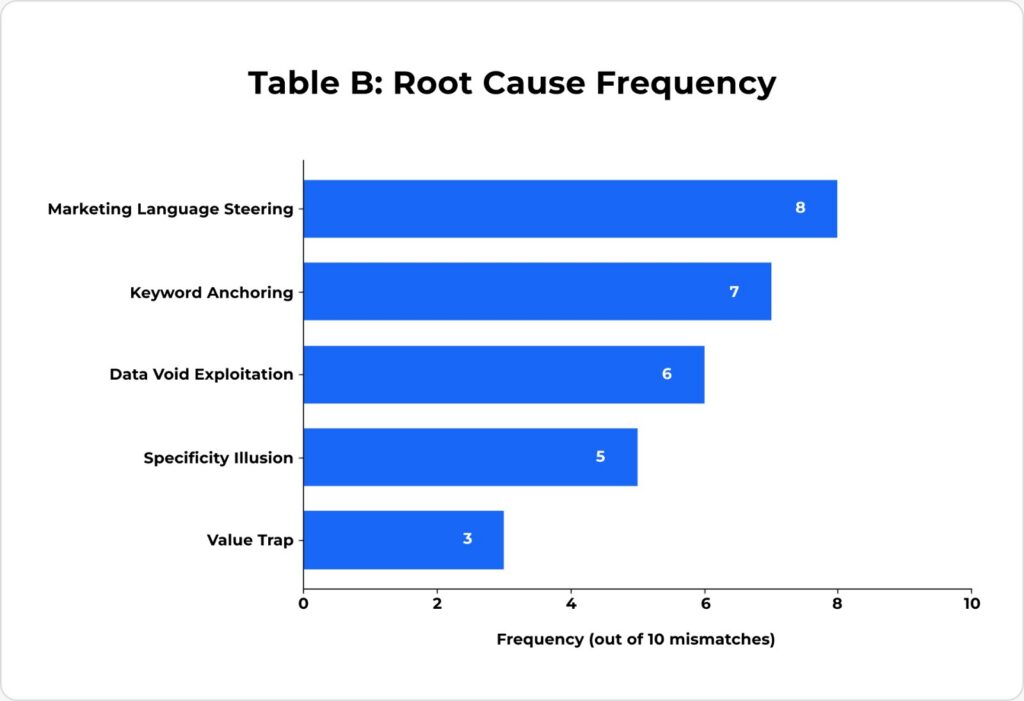
We identified 5 recurring patterns that caused description-only agents to make suboptimal selections:
Root Cause Pattern | Occurrences | Description |
Keyword Anchoring | 7/10 | The agent latched onto explicit keyword matches in descriptions that directly mirrored the user’s query terms, overriding deeper evaluation. |
Specificity Illusion | 5/10 | Technical-sounding or scientific language in descriptions created a false perception of superior quality (e.g., “advanced micro-ceramic technology”). |
Marketing Language Steering | 8/10 | Persuasive, aspirational copy was treated as factual evidence. Phrases like “at a price that can’t be beat” were weighted as proof of value leadership. |
Value Trap | 3/10 | Descriptions highlighted appealing attributes (low price, eco claims) while strategically omitting critical exclusions, limitations, or quality issues. |
Data Void Exploitation | 6/10 | When structured data was absent (no ratings, no specs), the agent defaulted to using marketing language as its primary decision signal. |
4.5 Analysis of Successful Matches
The 9 cases where descriptions successfully guided agents to the correct choice shared common traits:
Success Factor | Occurrences | Description |
Unique Differentiator | 6/9 | Only one product could plausibly satisfy the user’s primary requirement (e.g., only one zero-VOC paint, only one fermentation kit). |
Quantitative Anchor | 5/9 | Price or a measurable attribute was explicit and dominant, leaving little room for marketing to steer the decision. |
Factual Keyword Density | 7/9 | The description was rich with specific, verifiable facts rather than aspirational language. |
Primary Priority Dominance | 8/9 | The user’s primary priority was so strong that the description’s alignment with it was sufficient, even if secondary priorities were poorly served. |
5. The Solution: How to Win in the B2A Economy
Our experiment not only exposes the problem, it illuminates a clear path to solving it. The solution is a fundamental shift in how businesses structure, present, and expose their product data. Below are the concrete steps, each grounded in the patterns we observed in our research.
Step 1: Adopt the Model Context Protocol (MCP)
What it is: MCP is an open standard (often described as the “universal USB-C for AI”) that allows AI agents to connect directly with your product data through structured JSON schemas.
Why it matters from our data: In every mismatch case, the description-only agent was forced to interpret unstructured marketing text. When agents have access to structured, queryable data (as the full-data agent did), they make optimal selections. MCP eliminates the “data void” that forces agents to rely on marketing copy.
Action: Expose your product catalog through an MCP server. Allow agents to query specific attributes, price, features, compliance standards, coverage details, directly, without parsing prose.
Step 2: Optimize for Semantic Vector Search
What it is: AI agents don’t just match keywords, they convert your text into mathematical vectors and measure conceptual alignment with the user’s intent.
Why it matters from our data: We observed that agents were highly effective at semantic matching when descriptions contained factual keyword density specific, verifiable terms densely packed into the text. The EcoSpend Visa Terra matched correctly because its description contained multiple concrete eco-friendly anchors (“reclaimed ocean plastic,” “carbon-offset projects,” “sustainable brands”). By contrast, products with generic aspirational language were frequently mismatched.
Action: Replace vague marketing language with dense, factual descriptions. If your product uses premium ingredients, name them. If your service follows a specific process, describe it. Every claim should be verifiable.
Step 3: Structure Data for Just-in-Time Retrieval
What it is: AI agents use progressive disclosure; they don’t want your entire brochure. They want to retrieve specific facts on demand.
Why it matters from our data: In the insurance experiment, the agent selected a policy that explicitly excluded water backup (burst pipes) because the description strategically omitted this exclusion. If the coverage details had been structured as queryable data chunks, the agent could have checked “Does this cover water backup?” and immediately disqualified the product.
Action: Break your product data into semantic chunks: coverage details, pricing tiers, feature specs, compliance certifications. Each chunk should be independently retrievable.
Step 4: Survive the Reranking Phase
What it is: Production AI systems use a two-stage retrieval: broad search, then aggressive filtering (cross-encoder reranking) to narrow to the top 3–5 options.
Why it matters from our data: In several mismatch cases, the correct product was eliminated during the filtering stage because its description contained ambiguous or potentially disqualifying language. In the house painting experiment, a phrase about “furniture and floors” (intended to describe interior protection) was interpreted as a scope limitation, causing the cheapest viable option to be discarded entirely.
Action: Audit your descriptions for ambiguous language that could be misinterpreted as a limitation. Every phrase must be precise. If your service covers both interiors and exteriors, say so explicitly.
Step 5: Eliminate Marketing Fluff: It Actively Hurts You
Why it matters from our data: This is perhaps our most counterintuitive finding. Traditional marketing language doesn’t just fail to help with AI agents it actively harms your product’s chances. In the food truck experiment, a description filled with phrases like “unforgettable indulgence” and “culinary statement” lost to a competitor whose description simply listed factual ingredients and sourcing. The agent burned context tokens processing aspirational text and missed the critical specifications.
Action: Ruthlessly cut any text that doesn’t convey a verifiable fact or measurable attribute. Replace “an experience in pure indulgence” with “A5 Wagyu from Kagoshima, dry-aged 45 days, served on brioche from [named bakery].”
Step 6: Test Your Descriptions Against Agent Evaluation
Why it matters from our data: Every business in our experiment believed their marketing copy was effective. None had tested it against AI agent evaluation. The results were shocking, descriptions that performed brilliantly for human consumers frequently failed when evaluated by agents.
Action: Run agent-based A/B testing on your product descriptions. Submit your descriptions to AI agents alongside your competitors’ and measure selection rates. This is the new conversion optimization.
6. The B2A Testing Playbook: A Framework for Competitive Agent-Readiness
Knowing that product descriptions influence AI agent selection is necessary but insufficient. Businesses need a systematic, repeatable process for testing and improving their agent-facing interfaces, the same way they run QA on their websites, load-test their APIs, and A/B test their landing pages. This chapter provides that framework.
The Core Principle: Treat Agent-Facing Data as a Product
Your website is a product. Your API is a product. Your agent-facing data layer, the descriptions, schemas, and structured endpoints that AI agents consume, must now be treated with the same rigor. It needs testing environments, performance benchmarks, regression suites, and continuous optimization.
Phase 1: Audit – Map Your Agent-Facing Surface Area
Before you can test anything, you need to understand what AI agents currently see when they evaluate your products.
Step 1.1: Inventory every public data touchpoint. Catalog every place your product data exists in a form that an AI agent could access: website product pages, API responses, structured data markup (schema.org), marketplace listings, review aggregators, and any MCP or tool-use endpoints you expose. For each touchpoint, document what fields are present and what is missing.
Step 1.2: Perform a “description gap analysis.” For each product, create two columns: what your internal team knows about the product (true quality, sourcing, limitations, differentiators) and what the public-facing description actually communicates. Our experiment’s dual-layer methodology (Agent Data vs. Internal Quality Evaluation) is directly replicable. Every gap between these two columns is a vulnerability a place where an agent will be forced to guess, infer, or be steered by a competitor’s more complete data.
Step 1.3: Identify ambiguous or disqualifying language. Our research found that a single ambiguous phrase can cause an agent to disqualify a product entirely. Scan every description for language that could be misinterpreted as a scope limitation, exclusion, or negative quality signal. Flag any sentence that a literal-minded reader could interpret differently from your intent.
Phase 2: Simulate – Build Your Competitive Testing Arena
This is the heart of the framework. You must simulate how AI agents evaluate your product against your actual competitors.
Step 2.1: Construct a competitive dataset. Gather the public-facing descriptions of your top 5–10 competitors in each product category. Include their prices, feature claims, and any structured data they expose. This is your testing arena, the same marketplace an AI agent will navigate when a user asks for a recommendation.
Step 2.2: Define representative user personas and queries. Based on your customer segments, write 10–20 natural-language queries that reflect how real users would ask an AI agent to find a product like yours. Each query should include:
- A primary intent (e.g., “cheapest,” “most durable,” “most innovative”)
- A secondary intent (e.g., “but also trustworthy,” “with good reviews,” “eco-friendly”)
- Natural, conversational phrasing, not keyword searches
Our experiment used priority pairs like (lowest price + brand trust) and (innovation + eco friendliness). Your personas should map to your actual buyer segments.
Step 2.3: Run multi-model agent evaluations. Submit your competitive dataset and user queries to multiple AI models (GPT-4, Claude, Gemini, Llama, etc.). For each query, record which product the agent selects and, critically, why capture the agent’s reasoning. Different models have different biases and reasoning patterns. A product description that wins on one model may lose on another.
Step 2.4: Run dual-condition tests (the core of our methodology). For your own products, create both a “full-data” version (including internal quality notes and specs) and a “description-only” version (only what’s publicly available). Run the same queries against both. When the results diverge, you’ve found a description that is failing to communicate your product’s true value.
Phase 3: Measure – Define Your Agent-Readiness Scorecard
You need quantifiable metrics to track progress over time and prioritize fixes.
Metric 1: Selection Rate. For each user query, what percentage of the time does the agent select your product? Track this across models and across description versions. This is your “agent conversion rate.”
Metric 2: Match Rate. When you run dual-condition tests, how often does the description-only agent agree with the full-data agent? Our experiment found this at ~50%. Your target should be 80%+.
Metric 3: Influence Anchor Density. Count the number of specific, factual, verifiable claims per 100 words of description. Our research showed that descriptions with high factual density correlated strongly with correct agent selection. Track this as a leading indicator.
Metric 4: Disqualification Rate. How often is your product eliminated during the agent’s filtering phase not because it’s a bad match, but because your description contains ambiguous or potentially disqualifying language? This is a silent killer. If you’re never selected, you’ll never know why unless you measure this explicitly.
Metric 5: Priority Alignment Score. For each query, score how well the agent’s justification aligns with the user’s stated priorities. A product can be “selected” for the wrong reasons our data showed cases where descriptions led to correct selection but with inflated confidence based on marketing claims rather than factual alignment.
Phase 4: Optimize – The Iterative Improvement Cycle
Based on your measurements, systematically improve your agent-facing data.
Optimization 1: Close description gaps. For every mismatch between your full-data and description-only tests, identify exactly what information was missing from the description that caused the agent to choose differently. Add that information. Be specific: if your paint service includes full-surface sanding, say “full-surface sanding” don’t say “meticulous preparation.”
Optimization 2: Neutralize competitor keyword anchors. If a competitor’s description contains a phrase that acts as a powerful keyword anchor for a common user query (e.g., “at a price that can’t be beat”), ensure your description contains an equally strong or stronger factual counter-signal. The agent will weigh the specificity and verifiability of claims. “Our lowest price tier starts at $X/unit” beats “unbeatable prices.”
Optimization 3: Add structured data layers. Convert your most critical product attributes into structured, queryable formats. Expose an MCP server or enrich your API responses with typed fields for price, features, coverage details, certifications, and exclusions. The more structured data an agent has, the less it relies on parsing marketing prose.
Optimization 4: A/B test description variants. Run your competitive simulation with different versions of your product description. Measure selection rate changes. This is the agent-native equivalent of landing page A/B testing. Small changes in phrasing can produce dramatic shifts in agent selection, our data showed that a single phrase (“at a price that can’t be beat”) was sufficient to redirect an agent’s choice entirely.
Phase 5: Monitor – Establish Continuous Agent Regression Testing
Agent-readiness is not a one-time project. It is an ongoing operational discipline.
Monitor 1: Competitor description changes. Your competitors will eventually optimize their descriptions too. Set up monitoring for changes in competitor product pages, API schemas, and marketplace listings. When a competitor updates their description, re-run your competitive simulation to check if your selection rate has changed.
Monitor 2: Model updates and behavior shifts. AI models are updated frequently. A description that performs well on GPT-4o may perform differently on the next release. Run your test suite against new model versions as they ship.
Monitor 3: New query patterns. As AI assistant usage grows, user query patterns will evolve. Monitor how your customers actually phrase their requests to AI agents (via analytics, user research, or support logs) and update your test queries accordingly.
Monitor 4: Build agent-readiness into your release process. Every time a product description, pricing page, or API schema changes, run the agent simulation suite as part of your release pipeline, the same way you run unit tests before deploying code. No description goes live without passing agent-readiness checks.
The Testing Maturity Model
Level | Name | Description |
0 | Unaware | No testing of agent-facing data. Descriptions are written purely for human marketing. |
1 | Ad-Hoc | Occasional manual checks. Someone pastes the description into ChatGPT and asks “would you pick this?” |
2 | Structured | Formal competitive dataset exists. Regular simulation runs against 2–3 models. Metrics tracked quarterly. |
3 | Integrated | Agent-readiness tests are part of the product release pipeline. Competitor monitoring is automated. Metrics tracked monthly. |
4 | Optimized | Continuous A/B testing of description variants. Multi-model regression suite. Real-time competitor response. Agent-readiness is a KPI reported to leadership. |
Most businesses today are at Level 0. The findings in this report should move them to Level 1 immediately. The framework above provides the roadmap to Level 4.
7. Conclusion
Our research delivers a clear, data-backed verdict: the era of Business-to-Agent commerce has arrived, and most businesses are not ready.
When AI agents select products on behalf of users, they choose suboptimally more than half the time, not because the agents are flawed, but because the data they are given is. Marketing descriptions written for human emotions become noise in an algorithmic decision process. Worse, they can actively steer agents toward inferior products and away from superior ones.
The core findings that every business leader must internalize:
Product descriptions are no longer sales copy, they are machine-readable data infrastructure. Every word in your product description is now a signal that will be parsed, weighted, and compared algorithmically. Aspirational language burns context tokens. Vague claims create specificity illusions that advantage competitors. Missing data creates voids that marketing language from rivals will fill.
The competitive landscape has inverted. Traditionally, the business with the best marketing story won the customer. In the B2A economy, the business with the most structured, factual, and complete data wins the agent, and by extension, the customer. Our experiments showed that a competitor with a more strategically worded description can capture selection even when the objectively better product exists.
The cost of inaction is measurable. In our experiments, description-driven mismatches led to selections that cost users 67% more, recommended insurance policies that excluded the user’s primary risk concern, and selected products from competitors with unverified quality claims over those with documented operational excellence.
The solution is concrete and actionable. Adopt machine-readable protocols like MCP. Replace marketing fluff with factual density. Structure data for progressive retrieval. Audit descriptions for ambiguity. And above all, test your product data against AI agent evaluation, because that is where your next sale will be won or lost.
The companies that continue to optimize their digital presence exclusively for the human eye will watch their products become invisible to the fastest-growing purchasing channel in the economy. The future belongs to businesses that understand a fundamental truth: in the age of AI agents, your product data IS your product.

