Data-based decision-making systems are increasingly affecting people’s lives. Such systems decide whose credit loan application is approved, who is invited for a job interview and who is accepted into university. This raises the difficult question of how to design these systems, so that they are compatible with fairness and justice norms. Clearly, this is not simply a technical question – the design of such systems requires an understanding of the social context of these applications and requires us to think about philosophical questions.

Counterfactuals in XAI
In the field of XAI, counterfactuals provide interpretations to reveal what changes would be necessary in order to receive the desired prediction, rather than an explanation to understand why the current situation had a certain prediction. Counterfactuals help the user understand what features need to be changed in order to achieve a certain outcome and thus infer which features influence the model the most. Counterfactual instances can be found by iterative perturbing of the input features until the desired prediction or a prediction different than the original outcome is obtained. We focus on searching for a counterfactual solution in the input space to capture an unfair decision on the part of the model and mitigate bias or simply emphasize a wrong decision-making behavior caused by a bad data structure.
Counterfactuals in XAI
By using counterfactual explanations we prove and overcome the fragility and bias of a machine learning model. The scope of the research is to reduce the bias toward a specific feature or a set of features in the training dataset to increase the model fairness without altering the correlation value between the rest of the features on the outcome. Counterfactuals can be used as unit tests to measure the fragility of the model. Using the MNIST example a poorly trained model would have a reduced number of changes for a different outcome than the original, as opposed to a model that is trained well that will introduce more noise in the generated image.

Research Scope
The scope of this research is to reduce the bias toward a specific feature or a set of features in the training dataset to increase the model fairness without altering the correlation value between the rest of the features on the outcome. The paper focuses on measuring the quality of the generated counterfactuals, their impact on the feature importance / corre- lation, and increasing the model’s fairness with each batch of generated counterfactuals.
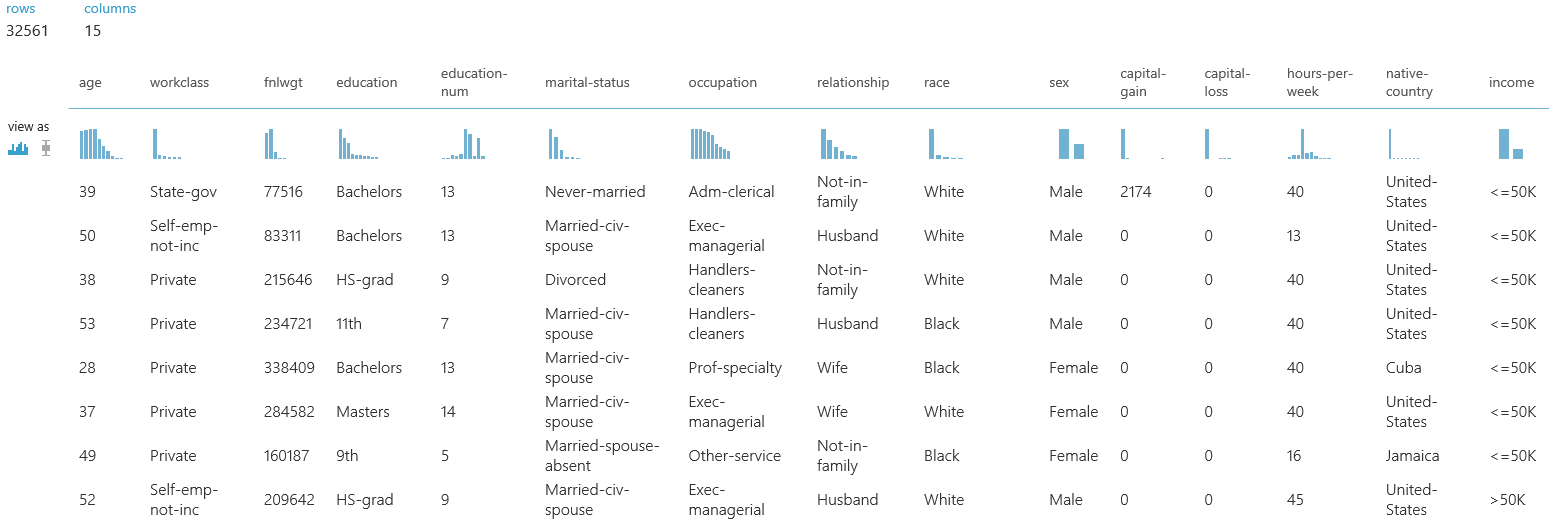
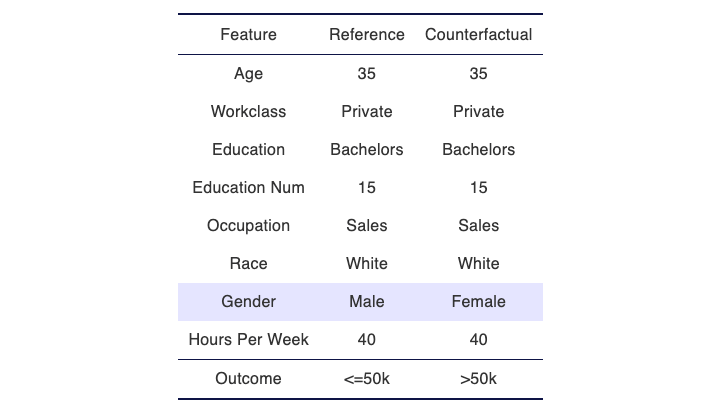
Sample Counterfactual
Results
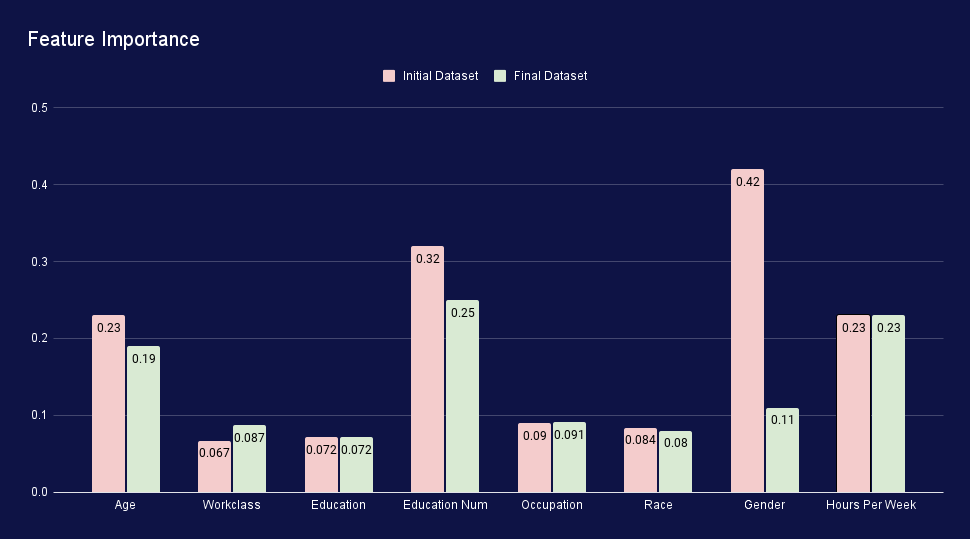
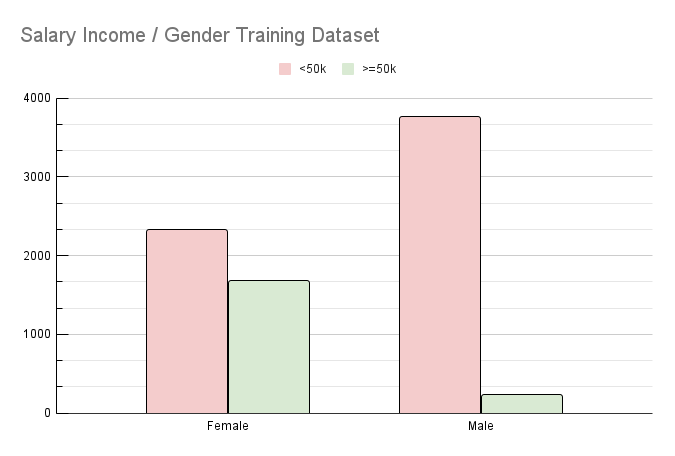
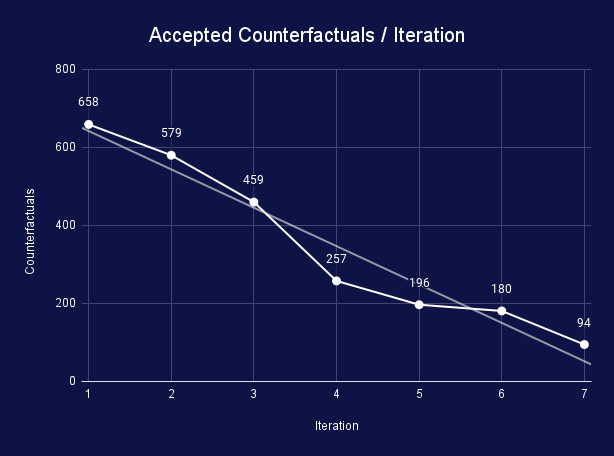
The counterfactuals were generated using seven iterations, each consisting of a batch of 1,000 samples for measurements and counterfactuals. The decrease of accepted solutions with each iteration results from an increase in model robustness and a proof that the generating algorithm finds fewer solutions or the found solutions have too many changes to be accepted. To evaluate the model fairness update, a benchmark dataset was used after each new batch of synthetic data was pushed back into the training dataset, and the model was updated. After each benchmark, we extracted the number of times each feature was changed for both generated and accepted solutions. For the initial iteration, Gender was the primary feature that was changed to generate a potential solution (696 potential solutions, 302 passing the threshold). As the model is updated and the fairness is corrected, later iterations observed a decrease in solutions with changes in Gender and mainly focused on other, more relevant to the real-world features, such as Age, Education Num and Hours per Week.
We computed the correlation matrix between each input feature against the output column (Salary Status) to monitor the influence of each feature on the outcome at the training dataset level. As shown in the figure below, the Gender feature influence on the outcome was highly diminished without significantly impacting the rest of the features. There are also other features that capture a personal characteristic, such as race, but since the original training data was not biased toward race, the feature importance of this column was not changed at the end of the iterative process. Also, features that do not contain any personal characteristic (e.g. Occupation, Hours per Week, Education) suffered a minor change at the end of the iterative process thus maintaining the original data characteristics.